Chcecie napisać wzorcowe API REST a może przerobić stare API? Postaram się przybliżyć Wam co trzeba widzieć i jakie kroki wykonać aby osiągną ten cel w glorii chwały.
Geneza REST
Zacznę od wytłumaczenia co to jest API (ang. Application Programming Interface) czyli interfejs programistyczny aplikacji jest to twór pozwalający na komunikację miedzy programami komputerowymi oraz wyznaczający zasady tej komunikacji. Jednym ze zbiorów takich zasad i reguł jest właśnie styl architektoniczny zwany REST (ang. REpresentational State Transfer) czyli po polskiemu „zmiana stanu poprzez reprezentacje”. Mam przeczucie, że nazwa nie powiedziała Wam za dużo, na końcu wszystko powinno być jaśniejsze.. Za powstaniem bohatera naszego artykułu stoi Pan Roy T. Fielding, który to także maczał palce, przy tworzeniu protokołu HTTP. Pan Fielding wziął na wokandę aplikację WWW (ang World Wide Web) i zaczął narzucać pewne ograniczenia, które później stały się bazowymi założeniami REST. Te ograniczenia to:
- CLIENT-SERVER – klient-server – separacja interfejsu od miejsca gdzie się przechowuje dane
- STATELESS – bez stanowość – niezawodność, łatwość skalowania
- CACHEABLE – podatność na cach’owanie – zwiększanie wydajności poprzez zapis w pamięci podręcznej
- UNIFORM INTERFACE – jednolity interfejs
Jest jeszcze jedno pojęcie, mocno związane z tematem REST. Są to RESOURCES – zasoby. Wszystko do czego możemy się odnieść, dane, które możemy pobrać są zasobem. Każdy zasób jest reprezentowany przez URI( Uniform Resource Identifier po naszemu Ujednolicony Identyfikator Zasobów) np. http://www.przyklad.pl/kruliczki.
Główne elementy doskonałego API REST’owego najlepiej przedstawia model dojrzałości Richardsona (Richardson Maturity Model). Model opracowany przez Leonarda Richardsona definiuje przy okazji kroki jakie trzeba wykonać, żeby przerobić „bagno” API na czyste API REST.
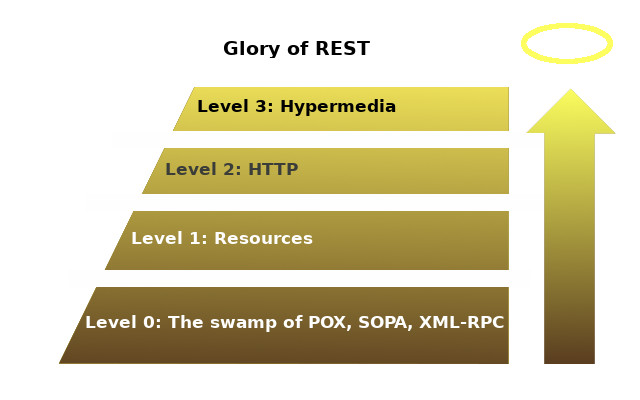
Według Richardson’a na początku jest tylko bagno SOAP, XML-RPC, itp- itd. Przez wprowadzenia pojęcia zasobów – URI, dodanie czasowników http i kontrolek hipermedia osiągamy stan nirwany – ideał.
To by było tyle w ramach wstępu. Teraz zgodnie z kolejnością pokazaną w modelu, przedstawię zasady tworzenia idealnego API w oparciu o styl architektoniczny REST.
Zasoby – URI – zasady tworzenia
Wiem już jak ważny w REST jest zasób oraz jak go reprezentować. Poniżej kilka wskazówek jak nazywać zasoby i jakie rodzaje URI stosować.
Najważniejsze to w nazwach URI nie używamy czasowników! Nazwy powinny zawierać tylko rzeczowniki i jeśli się da to w liczbie mnogiej. W praktyce używa się głównie dwóch rodzajów URI:
http://przyklad.pl/samochody – dostęp do całej kolekcji zasobów
http://przyklad.pl/samochody/12 – dostęp do konkretnego zasobu
Jeżeli chcemy pokazać hierarchię elementów przedzielamy je znakiem ‚/’. Natomiast w wypadku gdy chcemy zaznaczyć, że elementy są na tym samym poziomie używamy znaków ‚,’ lub ‚;’.
http://przyklad.pl/samochody/12/usterki
http://przyklad.pl/kwiatki/czerwony,niebieski
http://przyklad.pl/opony/zimowe;letnie
Jeżeli URI stają się zbyt skomplikowane i nieczytelne możemy użyć zwykłego query string’a
http://przyklad.pl/opony?sezon=zima&rozmiar=17
Pamiętajcie! Wzorowe API oparte na architekturze REST w nazwach linków nie zawiera czasowników.
Protokół HTTP
Ponieważ w URI nie ma czasowników, nie jesteśmy w stanie określić czynności jaką chcemy wykonać na zasobie, nasuwa się, więc pytanie jak to zdefiniować? I tu z pomocą przychodzi nam protokół HTTP a dokładnie metody jakie ten protokół udostępnia. Są to: GET, POST, PUT, DELETE. Jest ich więcej, ale na początek dobra znajomość tych czterech wystarczy.
Zanim poznacie przeznaczenie tych metod warto zapoznać się z pojęciami, które je definiują:
- bezpieczeństwo – metoda nie powoduje efektów ubocznych
- idempotentność – efekt wykonania za każdym razem jest taki sam, czyli dla stałego stanu systemu, rezultat kolejnego wykonania metody jest identyczny
Metoda GET
Metoda GET używana jest do zwracania zasobów. Powinna być bezpieczna i idempotentna. Dlaczego tak? Musimy pamiętać, że po tego typu URI przechodzą różnego rodzaju roboty internetowe. Wyobraźcie sobie sytuację w której URI z metodą GET usuwa jakiś zasób z waszego serwisu. Taki niewinny robocik, wędrujący po linkach twojego serwisu może narobić nie małego bałaganu.
GET http://przyklad.pl/samochody/12
Takie zapytanie zwróci konkretny samochód:
200 Success
{
"id": 12,
"marka": "Żuk",
"kolor": "czerwony"
}
Metoda POST
Metoda POST używana jest do dodawania zasobów. Metoda nie jest bezpieczna i idempotentna. Każdorazowe wywołanie operacji POST z takimi samymi danymi powoduje dodanie nowego zasobu z nowym identyfikatorem.
POST http://przyklad.pl/samochody
{
"marka": "Star",
"kolor": "zielony"
}
Zapytanie dodaje zasób do kolekcji z nowym id i zwraca odpowiedź:
201 Created
Dobra praktyką jest dodawanie nagłówka Location z URI do nowo stworzonego zasobu:
Location: http://przyklad.pl/samochody/13
Metoda PUT
Metoda głównie używana do podmiany zasobu o znanym identyfikatorze. Może ona posłużyć też do stworzenia zasobu, ale wtedy to my, a nie serwer, definiujemy identyfikator. Tak więc, metoda jest idempotentna, ale nie jest bezpieczna, ponieważ za każdym razem modyfikujemy ten sam zasób.
PUT http://przyklad.pl/samochody/13
{
"marka": "Star",
"kolor": "niebieski"
}
Zapytanie dodaje zasób do kolekcji z nowym id i zwraca odpowiedź:
200 Success
Ważne! Często tematem sporów jest to czy do tworzenia zasobu używać POST, czy PUT. Poniżej mala ściągawka rozwiązująca problem:
POST -> id pochodzi z serwera
PUT -> id pochodzi od klienta
Metoda DELETE
Najprostsza do zapamiętania. Służy, jak sama nazwa wskazuje, do usuwania zasobu lub zasobów. Metoda nie jest bezpieczna, ale jest idempotentna, ponieważ kasując wciąż wybrany zasób nie powinniśmy usunąć nic innego.
DELETE http://przyklad.pl/samochody – usuwanie całej kolekcji
DELETE http://przyklad.pl/samochody/13 – usuwanie konkretnego zasobu
Odpowiedź:
204 No content
Poniżej wykonałem tabelkę, podsumowującą informacje o poszczególnych metodach:
| /zasoby | /zasoby/123 | Kod odpowiedzi | Czy bezpieczna? | Czy idempotentna? | |
| GET | Pobierz wszystkie | Pobierz konkretny | 200 | TAK | TAK |
| POST | Stwór nowy | – | 201 | NIE | NIE |
| PUT | – | Zmodyfikuj | 200 | NIE | TAK |
| DELETE | Usuń wszystkie | Usuń konkretny | 204 | NIE | TAK |
Hypermedia – linkowanie
Wyobraźmy sobie jak przeglądamy jakiś serwis w internecie. Podróżowanie po nim umożliwiają nam linki w menu, breadcrumb, stopce oraz zaszyte w treści. Prawidło zbudowany serwis udostępnia możliwość dojścia do każdego miejsca serwisu i powrotu z tego miejsca na początek przeglądania. Bez prawidłowo zbudowanej struktury linków nie bylibyśmy w stanie podróżować po serwisie, odkrywać wszystkich jego funkcjonalności i zależności. Stanowi to dla nas jakąś formę opisu serwisu.
Dlaczego by nie wprowadzić podobnej formy opisu w API. Autorzy REST wyszli z tego założenia i postanowili dodać ten wymóg w dogmacie naszego stylu architektonicznego. Założeniem hypermedia jest to, żeby w zwrotce z metody API oprócz pobieranych danych dodawać też kolekcję linków związanych z danym zasobem. Specjaliści od REST zalecają też dodanie linku do zasobu, który właśnie pobieramy, tak zwany link „self”. Jak to wygląda na przykładzie:
{
"_links": [
{"rel": "self", "uri": "/samochody/12"}
{"rel": "usterki", "uri": "/samochody/12/usterki"}
].
"id": 12,
"marka": "Żuk",
"kolor": "czerwony"
}
Jak widać na przykładzie metoda zwróciła dodatkowe pole w odpowiedzi zwane „_links” które zawiera informację o rodzaju relacji i URI z nią związanej.
Używając linków zyskujemy samo opisywalność się naszego API, widzimy dokładnie możliwości naszego serwisu oraz wszystkie połączenia i zależności miedzy poszczególnymi zasobami.
Ważne pojęcia
Na koniec dodam jeszcze dwa pojęcia, które przydadzą się do błyśniecie w czasie długich dyskusji o REST.
Nasze zasoby i hyperlink’i tworzą domenowy protokół aplikacji (ang. Domain Application Protocol), czyli zestaw reguł i konwencji regulujących interakcje między członkami aplikacji rozproszonej.
Drugie pojęcie to HATEOAS (ang. Hypermedia As The Engine Of Application State ). Po polskiemu się mówi tak hypermedia jako silnik stanu aplikacji. Chodzi tu o to, że jako klient API wędrując po likach naszego API przy każdym kroku znajduje się w jakimś stanie. Przejścia po kolejnych URI powodują zmiany stanu, dokładnie je opisując poprzez dostarczanie kolejnych URI, a zarazem nowych możliwości ruchu.
Drugie pojęcie przynosi nam też genezę nazwy REST. Reprezentacja to nasz zasób, a zmiany stanu dokonujemy poprzez modyfikacje tego zasobu i przechodzenie do kolejnych URI.
W powyższym poście powinniście znaleźć wszystko co jest potrzebne by zacząć tworzyć lub przenosić stare API do REST. Pominąłem między innymi temat kodów HTTP, nie mniej ważny, dlatego uważam że zasługuje on na oddzielny wpis. W kolejnych postach postaram się też pokazać REST w praktyce oraz przyjrzeć się dokładnie wybranym zagadnieniom.
![]()